Action #1305

Understand why diffuse emission fitting takes so many iterations
| Status: | Closed | Start date: | 07/29/2014 | |
|---|---|---|---|---|
| Priority: | Normal | Due date: | ||
| Assigned To: |  Knödlseder Jürgen Knödlseder Jürgen | % Done: | 100% | |
| Category: | - | |||
| Target version: | 00-09-00 | |||
| Duration: |
diffuse_unbinned_scale5_SrcIndex.png (50.2 KB)
diffuse_unbinned_scale5_Sigma.png (49.3 KB)
diffuse_unbinned_scale5_BkgPrefactor.png (52.4 KB)
diffuse_unbinned_scale5_BkgIndex.png (44.6 KB)
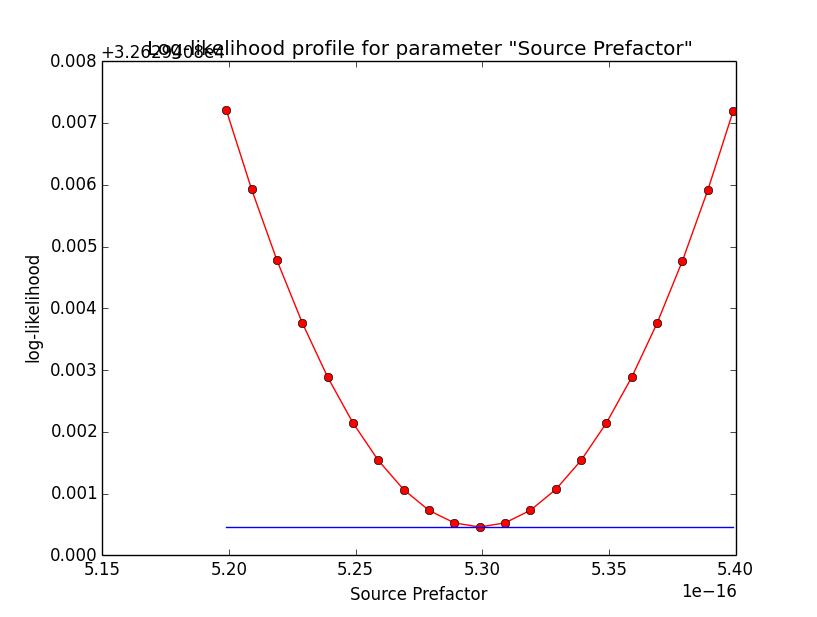
diffuse_unbinned_scale5_SrcPrefactor.png (46.2 KB)
diffuse_unbinned_scale5_Index_opt6.png (48.4 KB)
diffuse_unbinned_scale5_Index_opt8.png (47.4 KB)
diffuse_unbinned_scale5_Index_opt10.png (40 KB)



Recurrence
No recurrence.
Related issues
History
#1
 Updated by Knödlseder Jürgen over 10 years ago
Updated by Knödlseder Jürgen over 10 years ago
- File diffuse_unbinned_scale5_SrcPrefactor.png added
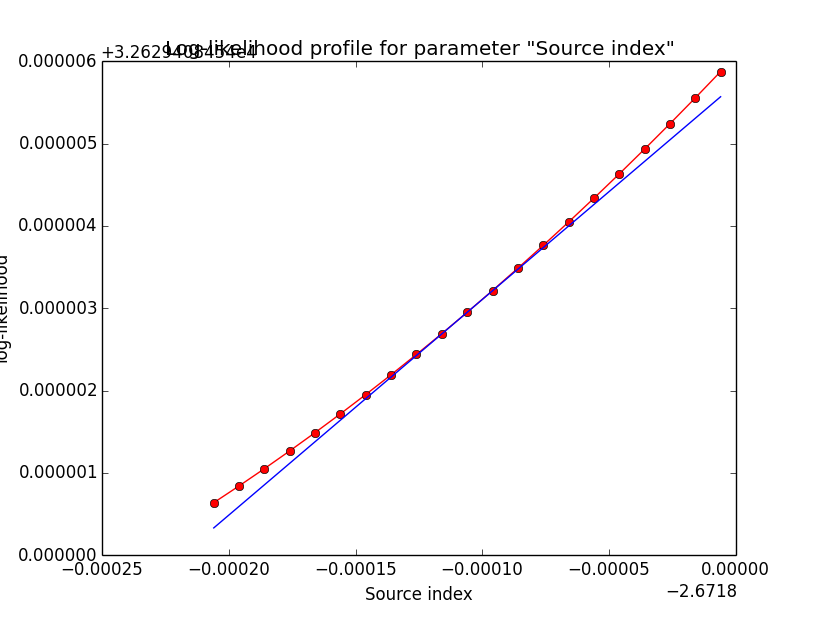
- File diffuse_unbinned_scale5_SrcIndex.png added
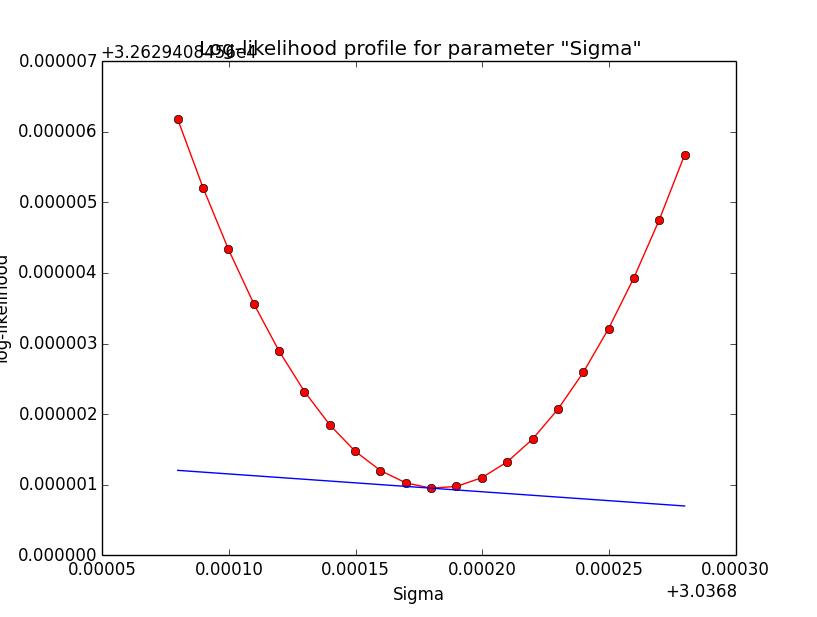
- File diffuse_unbinned_scale5_Sigma.png added
- File diffuse_unbinned_scale5_BkgPrefactor.png added
- File diffuse_unbinned_scale5_BkgIndex.png added
- Status changed from New to In Progress
- Assigned To set to Knödlseder Jürgen
Here the output of the optimizer when fitting the diffuse model in an unbinned analysis:
>Iteration 0: -logL=32632.073, Lambda=1.0e-03 >Iteration 1: -logL=32632.024, Lambda=1.0e-03, delta=0.049, max(|grad|)=-70.118144 [Index:7] Iteration 2: -logL=32632.024, Lambda=1.0e-04, delta=-0.519, max(|grad|)=-30.237027 [Index:2] (stalled) Iteration 3: -logL=32632.024, Lambda=1.0e-03, delta=-0.389, max(|grad|)=-29.206366 [Index:2] (stalled) >Iteration 4: -logL=32631.434, Lambda=1.0e-02, delta=0.590, max(|grad|)=-21.309557 [Index:2] Iteration 5: -logL=32631.434, Lambda=1.0e-03, delta=-0.893, max(|grad|)=-54.630362 [Index:7] (stalled) Iteration 6: -logL=32631.434, Lambda=1.0e-02, delta=-0.570, max(|grad|)=-41.063943 [Index:7] (stalled) >Iteration 7: -logL=32629.450, Lambda=1.0e-01, delta=1.984, max(|grad|)=4.124423 [Sigma:5] >Iteration 8: -logL=32629.412, Lambda=1.0e-02, delta=0.038, max(|grad|)=1.424688 [Index:7] Iteration 9: -logL=32629.412, Lambda=1.0e-03, delta=-0.004, max(|grad|)=-1.126451 [Index:7] (stalled) Iteration 10: -logL=32629.412, Lambda=1.0e-02, delta=-0.002, max(|grad|)=-0.771307 [Index:7] (stalled) >Iteration 11: -logL=32629.409, Lambda=1.0e-01, delta=0.003, max(|grad|)=0.751852 [Index:7] >Iteration 12: -logL=32629.409, Lambda=1.0e-02, delta=0.000, max(|grad|)=-0.163063 [Index:2] Iteration 13: -logL=32629.409, Lambda=1.0e-03, delta=-0.000, max(|grad|)=-0.334147 [Index:7] (stalled) Iteration 14: -logL=32629.409, Lambda=1.0e-02, delta=-0.000, max(|grad|)=-0.227450 [Index:7] (stalled) >Iteration 15: -logL=32629.409, Lambda=1.0e-01, delta=0.000, max(|grad|)=0.237633 [Index:7] >Iteration 16: -logL=32629.409, Lambda=1.0e-02, delta=0.000, max(|grad|)=-0.064887 [Index:2] Iteration 17: -logL=32629.409, Lambda=1.0e-03, delta=-0.000, max(|grad|)=-0.130886 [Index:7] (stalled) Iteration 18: -logL=32629.409, Lambda=1.0e-02, delta=-0.000, max(|grad|)=-0.088992 [Index:7] (stalled) >Iteration 19: -logL=32629.408, Lambda=1.0e-01, delta=0.000, max(|grad|)=0.096239 [Index:7] >Iteration 20: -logL=32629.408, Lambda=1.0e-02, delta=0.000, max(|grad|)=-0.026185 [Index:2]
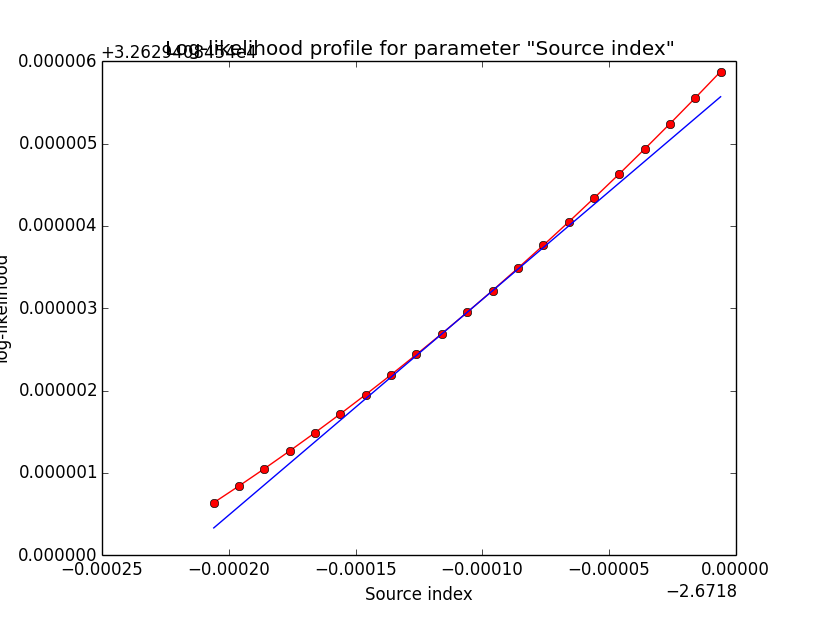
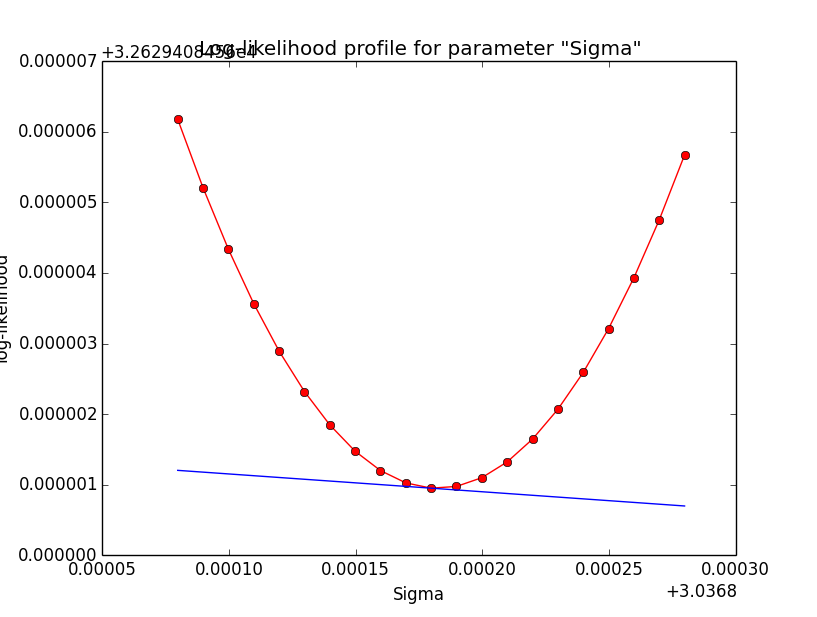
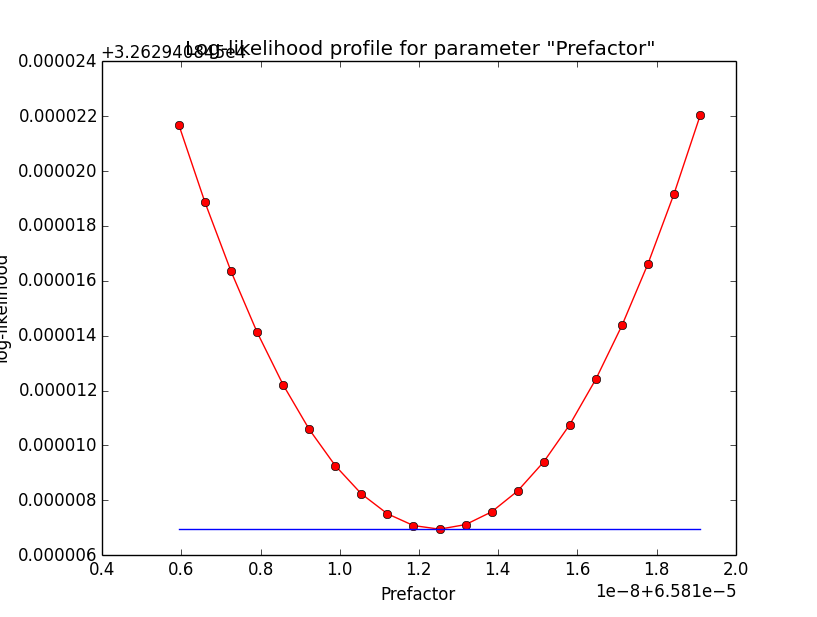
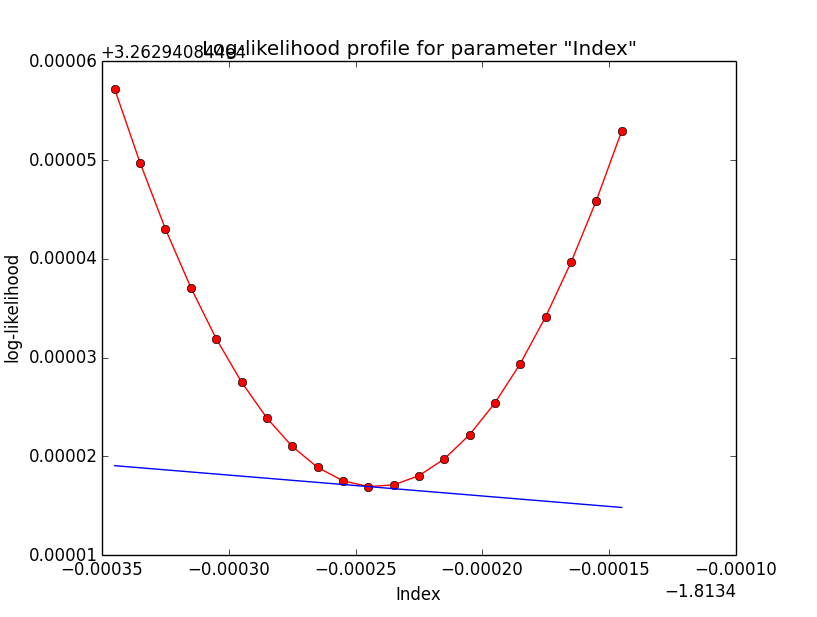
It looks like that the spectral indices have the largest gradients. Below the corresponding log-likelihood profiles. Top row are the source parameters (Prefactor and Index), bottom row are the background parameters (Prefactor, Index, Sigma). While the background parameters have smooth log-likelihood profiles and seems to be well fit, the source Index log-likelihood profile indicates that a minima has not been reached.
 |
 |
|
 |
 |
 |
#2
Updated by Knödlseder Jürgen over 10 years ago
- File diffuse_unbinned_scale5_SrcPrefactor.png added
#3
Updated by Knödlseder Jürgen over 10 years ago
- File deleted (
diffuse_unbinned_scale5_SrcPrefactor.png)
#4
Updated by Knödlseder Jürgen over 10 years ago
- % Done changed from 0 to 10
I played around with the various integration precision in the Irf and Npred computation without any notable change in the number of iterations required for the fit or in the log-likelihood profile of the spectral index.
#5
Updated by Knödlseder Jürgen over 10 years ago
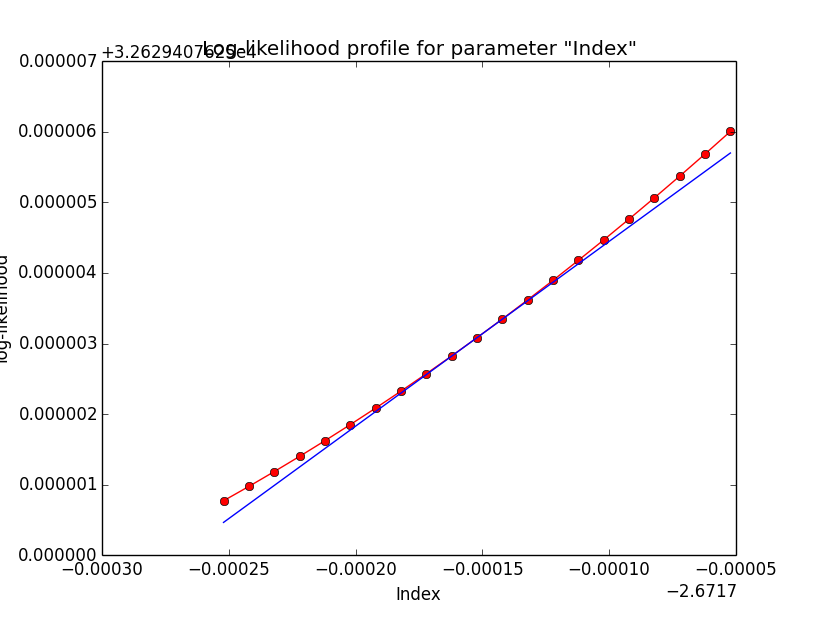
- File diffuse_unbinned_scale5_Index_opt6.png added
- File diffuse_unbinned_scale5_Index_opt8.png added
- File diffuse_unbinned_scale5_Index_opt10.png added
- Status changed from In Progress to Feedback
- Target version set to 00-09-00
- % Done changed from 10 to 100
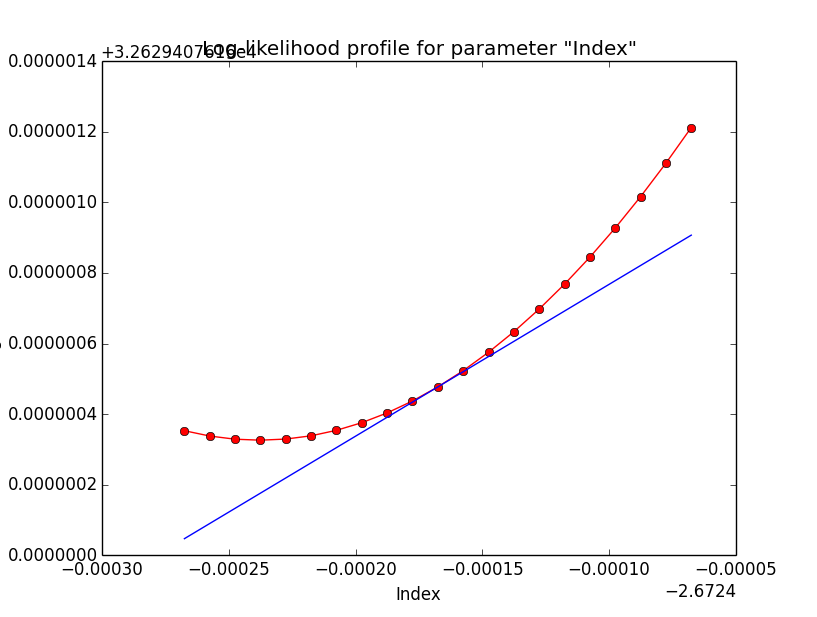
Maybe this is just a question of fit precision. Increasing the requirement on the optimizer precision increases the number of iterations but leads to a better minimum in the spectral index, as indicated in the plots below that show the log-likelihood profile for a precision of 1e-6 (left), 1e-8 (centre) and 1e-10 (right).
 |
 |
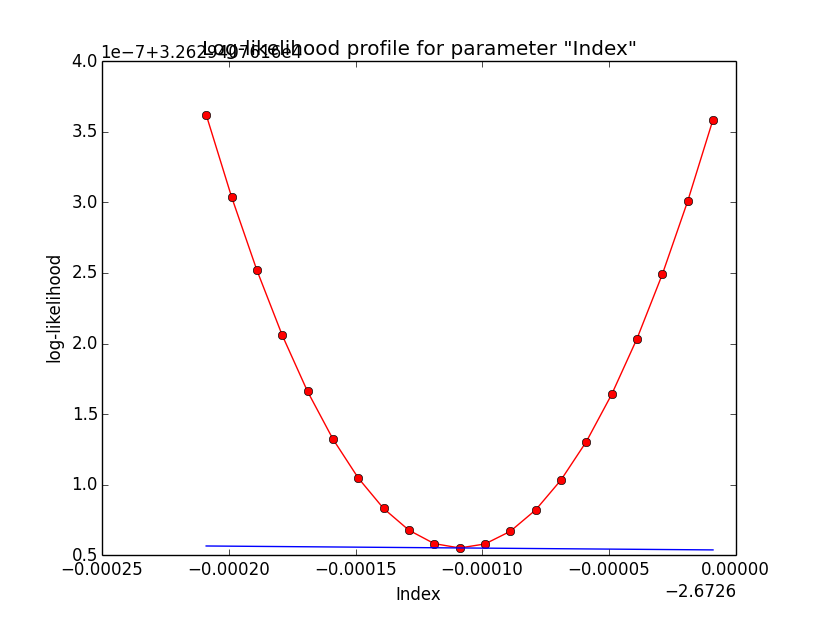 |
The table below shows the fit results as function of requested precision:
| Precision | Iterations | logL | Source prefactor | Source index |
| 1e-3 | 12 | 32629.408 | 5.2979e-16 +/- 1.7579e-16 | - 2.66745 +/- 0.274641 |
| 1e-4 | 12 | 32629.408 | 5.2979e-16 +/- 1.7579e-16 | - 2.66745 +/- 0.274641 |
| 1e-5 | 16 | 32629.408 | 5.29886e-16 +/- 1.75762e-16 | - 2.67059 +/- 0.275209 |
| 1e-6 | 20 | 32629.408 | 5.29943e-16 +/- 1.75752e-16 | - 2.67185 +/- 0.275427 |
| 1e-7 | 24 | 32629.408 | 5.29967e-16 +/- 1.75748e-16 | - 2.67236 +/- 0.275514 |
| 1e-8 | 28 | 32629.408 | 5.29977e-16 +/- 1.75746e-16 | - 2.67257 +/- 0.27555 |
| 1e-9 | 32 | 32629.408 | 5.29978e-16 +/- 1.75746e-16 | - 2.6726 +/- 0.275556 |
| 1e-10 | 82 | 32629.408 | 5.29984e-16 +/- 1.75745e-16 | - 2.67271 +/- 0.275574 |
So the results do not depend sensitively on the precision, but the gradients do. Note that the default GOptimizeLM precision is 1.0-6, which is also the value used in ctlike.
The question remains why the fit needs so many iterations? Possibly do to the diffuse nature of the source, which leads to a pretty strong correlation of source and background model. The biggest gradients are observed in the index of the background and the source model, and the fit alters between improvements and stalls. Maybe this could be changed if the full Hessian would be used in the fitting, but with the present scheme it looks like we have to live with this.
#6
Updated by Knödlseder Jürgen about 10 years ago
- Status changed from Feedback to Closed
- Remaining (hours) set to 0.0