Feature #1009
add Broken power law to spectral model
| Status: | Closed | Start date: | 12/02/2013 | |
|---|---|---|---|---|
| Priority: | Normal | Due date: | ||
| Assigned To: | % Done: | 100% | ||
| Category: | - | |||
| Target version: | 00-08-00 | |||
| Duration: |
Description
add the broken power law as spectral model, following the Fermi LAT implementation, similar to log parabola implementation
see Issue 605 [[ https://cta-redmine.irap.omp.eu/issues/605]].
bpl_trials5000.pdf - broken power law pull distributions
(171 KB)

bpl_trials5000_range4.png (82.7 KB)
{kind=link}
pl_trials5000_range4.png (77.6 KB)
{kind=link}
logp_trials5000_range4.png (52.2 KB)
{kind=link}
prefacor-fixed-scale.png (44.8 KB)
prefactor-fitted-scale.png (31.3 KB)
Recurrence
No recurrence.
Related issues
History
#1
 Updated by Knödlseder Jürgen about 11 years ago
Updated by Knödlseder Jürgen about 11 years ago
- Status changed from New to In Progress
- % Done changed from 0 to 50
I’ve seen your code in the git repo and did some minor code formatting.
I have seen that you had a parameter named “BreakEnergy” in the XML methods, but the Fermi/LAT name is “BreakValue”. I guess you want to be compatible with Fermi/LAT so that XML files can be used directly. I thus changed the parameter name to “BreakValue”.
I also have added a unit test to the test_GModel file, inspired by the unit test for the other spectral models. I created a XML file for this unit test in test/data.
Finally, I merged the actual devel branch into your feature branch as many things have changed recently. This will make merging of your feature branch into the devel branch easier once it’s ready.
Let me know if you need some help with the mc() method.
#2
 Updated by Schulz Anneli about 11 years ago
Updated by Schulz Anneli about 11 years ago
Hi Jürgen,
thanks for merging. I worked on the mc method today ( and committed it) but it somehow is not completely done. I tried to make it similar to the Nodes model. The code compiles and the fitting is working.
But if I check for the pull distributions I don’t have errors on the parameters and therefore get no proper pull distribution.
If I do a ctobssim I have a lot of photons, but no events:
2013-12-16T17:32:20: +======================+ 2013-12-16T17:32:20: | Simulate observation | 2013-12-16T17:32:20: +======================+ 2013-12-16T17:32:20: === Observation === 2013-12-16T17:32:20: Simulation area ...........: 1.9635e+11 cm2 2013-12-16T17:32:20: Simulation cone ...........: RA=83.63 deg, Dec=22.01 deg, r=10.5 deg 2013-12-16T17:32:20: Time interval .............: 0 - 1800 s 2013-12-16T17:32:20: Energy range ..............: 100 GeV - 100 TeV 2013-12-16T17:32:21: MC source photons .........: 681981 [Crab] 2013-12-16T17:32:21: MC source events ..........: 0 [Crab] 2013-12-16T17:32:21: MC source events ..........: 0 (all source models)
#3
Updated by Knödlseder Jürgen about 11 years ago
- % Done changed from 50 to 60
I see
// Get random energy for specific bin
if (m_mc_exp[inx] != 0.0) {
double e_min = m_mc_min[inx];
double e_max = m_mc_max[inx];
double u = ran.uniform();
double eng = (u > 0.0)
? std::exp(std::log(u * (e_max - e_min) + e_min) / m_mc_exp[inx])
: 0.0;
energy.MeV(eng);
}
else {
double e_min = m_mc_min[inx];
double e_max = m_mc_max[inx];
double u = ran.uniform();
double eng = std::exp(u * (e_max - e_min) + e_min);
energy.MeV(eng);
}
energy.MeV(0.0); // IS THIS THE PROBLEM ???
// Return energy
return energy;
in the code, hence all energies are 0.
After removing that line I get
2013-12-16T20:49:17: +======================+ 2013-12-16T20:49:17: | Simulate observation | 2013-12-16T20:49:17: +======================+ 2013-12-16T20:49:17: === Observation === 2013-12-16T20:49:17: Simulation area ...........: 1.9635e+11 cm2 2013-12-16T20:49:17: Simulation cone ...........: RA=83.63 deg, Dec=22.01 deg, r=10.5 deg 2013-12-16T20:49:17: Time interval .............: 0 - 1800 s 2013-12-16T20:49:17: Energy range ..............: 100 GeV - 100 TeV 2013-12-16T20:49:17: MC source photons .........: 202235 [Crab] 2013-12-16T20:49:17: MC source events ..........: 831 [Crab] 2013-12-16T20:49:17: MC source events ..........: 831 (all source models)
Seems to work now (just pushed change in feature branch).
Could you check if the pull distributions are okay?
#4
Updated by Schulz Anneli about 11 years ago
Hi Jürgen,
thanks again. That was really a stupid thing - it was just to check in the debugging phase. Sometimes it’s better to not do things after a long day.
I had a look at the distributions, but it’s still not properly working. The pull values are far too small ( since the errors of the fit are really huge) as you can see below.
I think it’s a problem in the gradient evaluation ?
Prefactor ................: 9.99745e-10 +/- 1.80261e-07 [1e-12,1e-06] ph/cm2/s/MeV (free,scale=1e-09,gradient) Index1 ...................: -1.79687 +/- 83157.5 [-5,-1] (free,scale=1,gradient) BreakValue ...............: 996.559 +/- 100000 [30,2000] MeV (free,scale=1,gradient) Index2 ...................: -2.30004 +/- 83157.5 [-5,-1] (free,scale=1,gradient)
I did a short check with log p as spectral model but there I have similar error values. For the power law it looks fine though.#5
Updated by Knödlseder Jürgen about 11 years ago
- % Done changed from 60 to 80
There were two bugs in the parameter gradient computation.
First, the wrong index was used to compute the break value gradient.
Second, the index gradients were both computed, irrespectively of the energy. However, if the energy is smaller than the break energy, only the first index gradient should be computed while the second will be 0. If the energy is larger, the first index gradient should be 0 and only the second should be computed.
Both bugs have been fixed.
For the record, here the ctlike results I obtained using the XML file in test/data:
Original:
2013-12-18T11:08:44: Prefactor ................: 5.70355e-16 +/- 6.70144e-16 [1e-23,1e-13] ph/cm2/s/MeV (free,scale=1e-16,gradient) 2013-12-18T11:08:44: Index1 ...................: -2.45723 +/- 1.32636e+06 [-0,-5] (free,scale=-1,gradient) 2013-12-18T11:08:44: BreakValue ...............: 300159 +/- 134603 [10000,1e+09] MeV (free,scale=1e+06,gradient) 2013-12-18T11:08:44: Index2 ...................: -2.71724 +/- 1.32636e+06 [-0.01,-5] (free,scale=-1,gradient)
Correct index for break value gradient computation:
2013-12-18T11:20:00: Prefactor ................: 5.70316e-16 +/- 6.62478e-16 [1e-23,1e-13] ph/cm2/s/MeV (free,scale=1e-16,gradient) 2013-12-18T11:20:00: Index1 ...................: -2.45912 +/- 2.09715e+06 [-0,-5] (free,scale=-1,gradient) 2013-12-18T11:20:00: BreakValue ...............: 300064 +/- 136298 [10000,1e+09] MeV (free,scale=1e+06,gradient) 2013-12-18T11:20:00: Index2 ...................: -2.71583 +/- 2.09715e+06 [-0.01,-5] (free,scale=-1,gradient)
Correct index gradient computation:
2013-12-18T11:22:10: Prefactor ................: 7.04161e-16 +/- 6.19095e-16 [1e-23,1e-13] ph/cm2/s/MeV (free,scale=1e-16,gradient) 2013-12-18T11:22:10: Index1 ...................: -2.36052 +/- 0.156732 [-0,-5] (free,scale=-1,gradient) 2013-12-18T11:22:10: BreakValue ...............: 283441 +/- 95901.2 [10000,1e+09] MeV (free,scale=1e+06,gradient) 2013-12-18T11:22:10: Index2 ...................: -2.7426 +/- 0.0564966 [-0.01,-5] (free,scale=-1,gradient)
The index errors look now more reasonable.
#6
Updated by Schulz Anneli about 11 years ago
- File bpl_trials5000.pdf added
Hi Jürgen,
again thanks. Just to keep you up to date:
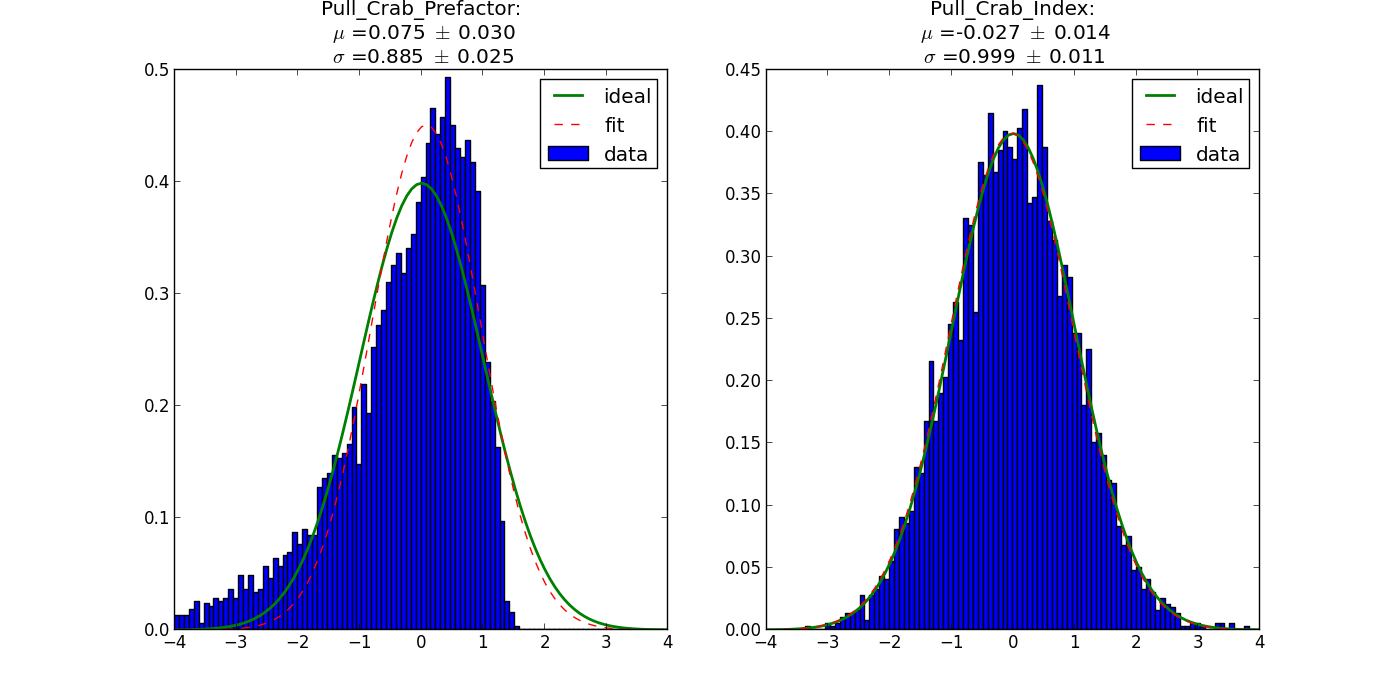
I had a look at the pull distributions( with 5000 trials) and there is still something wrong as you can see from the attached plot. The distribution for the indices look ok, but pre factor and break value are too narrow.
I will try to find out what the problem is.
#7
Updated by Schulz Anneli about 11 years ago
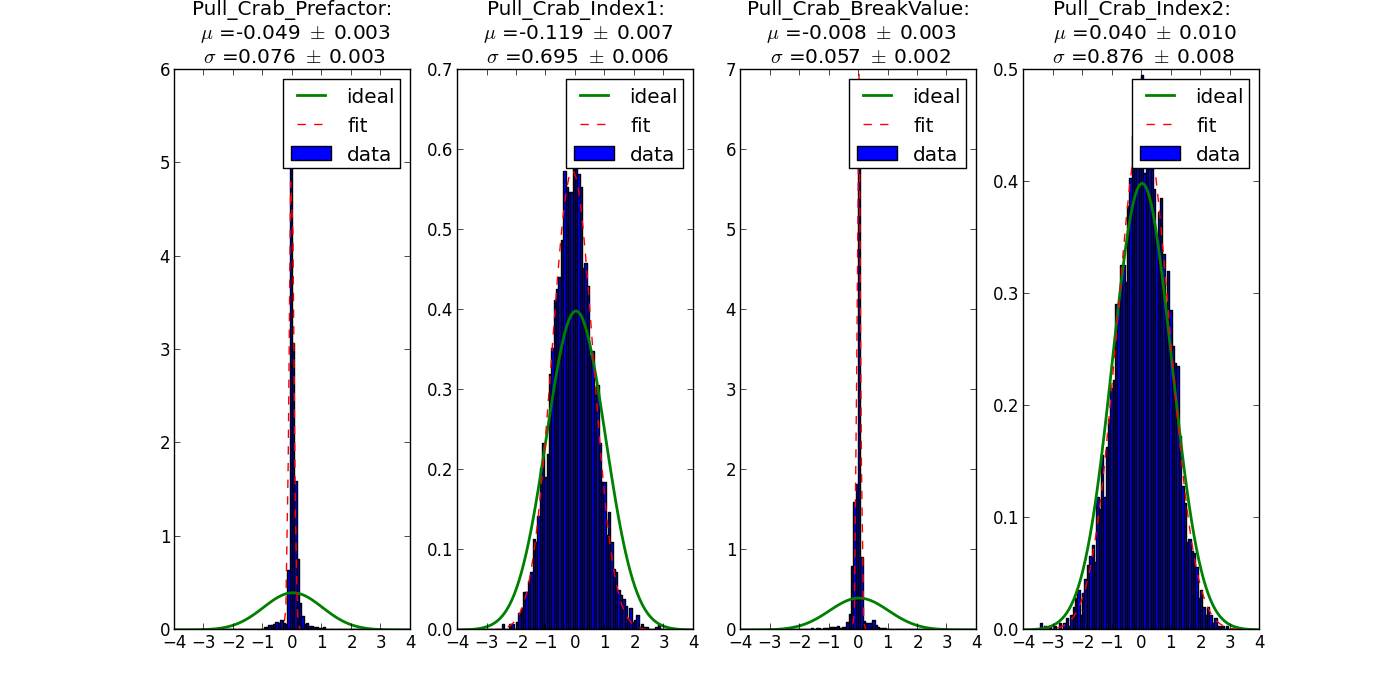
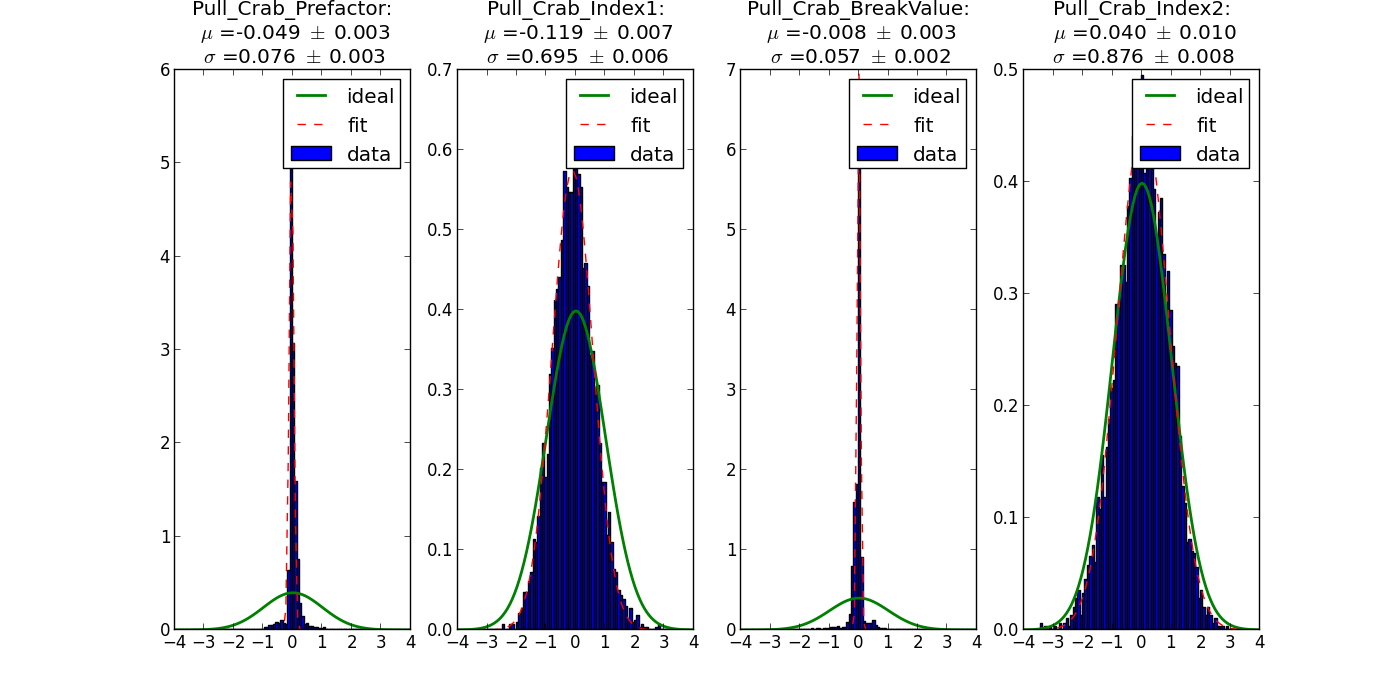
- File bpl_trials5000_range4.png added
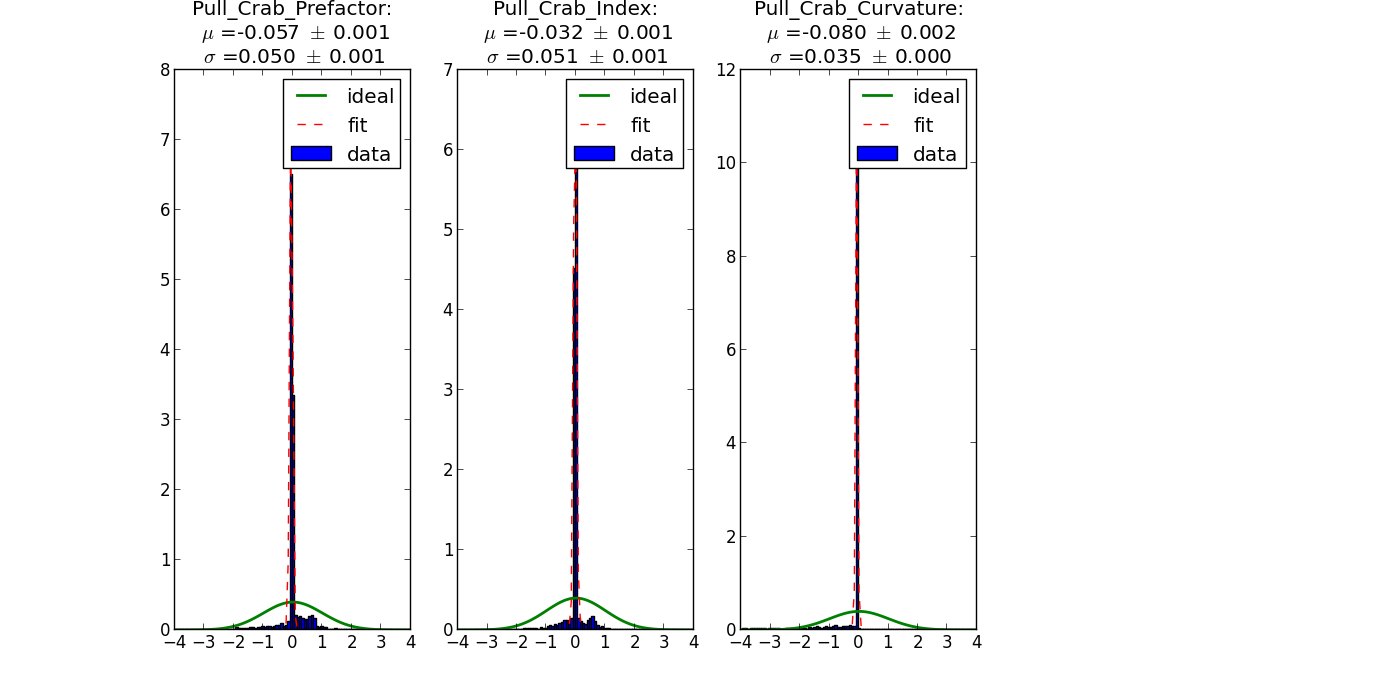
- File pl_trials5000_range4.png added
- File logp_trials5000_range4.png added
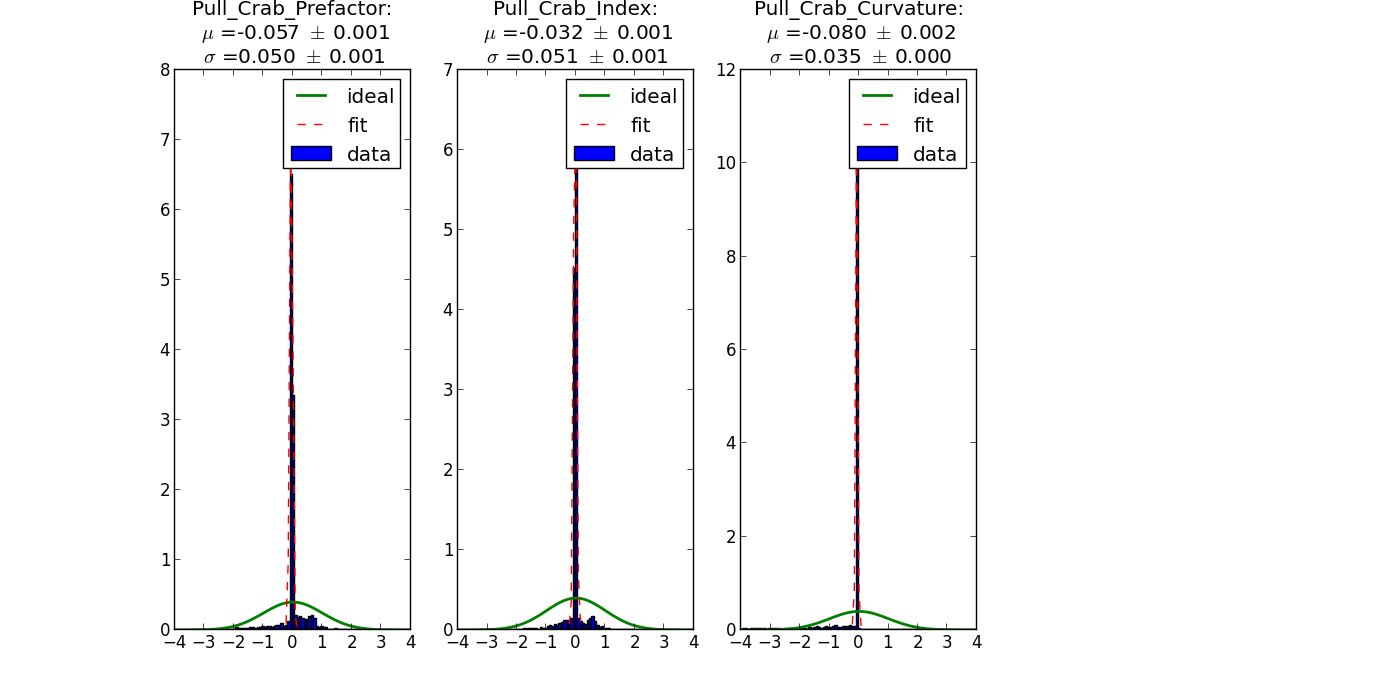
Looking a bit more into the pull distributions I found out that only Index2 is fine. The other distributions are too narrow.

I checked with a power law: there the distributions are fine:

but for log parabola the distributions are also too narrow:

(the distribution is with logo from before the fix from dec. 30th 2013 in devel, but they don’t change significantly after the fix)
The reason is that the errors for the parameters are large, resulting in a narrow distribution. An additional thing is that for log parabola and broken power law there are many entries with error == 0.
#8
Updated by Knödlseder Jürgen about 11 years ago
This looks a little bit like a statistical problem. Your pull prefactor is very skewed. Could it be that your simulations have only a very small number of events (i.e. you’re using probably a very short observing time)? In this case there may be not enough events to really constrain the model.
Have a look at
https://cta-redmine.irap.omp.eu/projects/gammalib/wiki/GModelSpectralNodes
which illustrates the problem.
#9
Updated by Knödlseder Jürgen about 11 years ago
I was trying to reproduce the pull distributions.
On my side, the log-parabola distributions look okay.
Yet I also see problem with the broken power law. It seems to be related to the fitting of the break energy, the prefactor distribution becomes better once I fix the break energy. The same is by the way true for the power law model: if I free the pivot energy, the distribution becomes too narrow.
#10
Updated by Schulz Anneli about 11 years ago
- % Done changed from 80 to 100
Hi Jürgen,
you are right. Extending the simulated exposure time and fixing the Breakenergy solves the problem with the pull distributions. Thanks. This means that the feature is now implemented and ready to be merged in the devel branch. Or is there something else to do?
#11
Updated by Knödlseder Jürgen about 11 years ago
Well, I think that the model is indeed ready, but you unveiled a more fundamental problem that I’m about to track down.
The break energy is in fact ill defined if the power law indices are similar. For identical indices, the break energy and the prefactor are in fact 100% degenerate. This can be seen when freeing the pivot energy for the Plaw model, which does not really make sense, but is in principle possible.
I think that GammaLib is actually not handling the errors for degenerate parameters properly. This is linked to an approximation that is taken in computing the curvature matrix used for error estimation. The code makes use of the approximate curvature matrix used in the Levenberg-Marquardt algorithm, which drops the second derivatives. This is okay for minimization, but may pose problems for error estimation.
I will look into this and then probably file a change request that asks for implementing a correct computation of the curvature matrix. I was in fact always surprised that the approximation works so well (as demonstrated by the fact that most pull distributions are okay), but it may be that it breaks down for degenerate parameters.
#12
Updated by Knödlseder Jürgen about 11 years ago
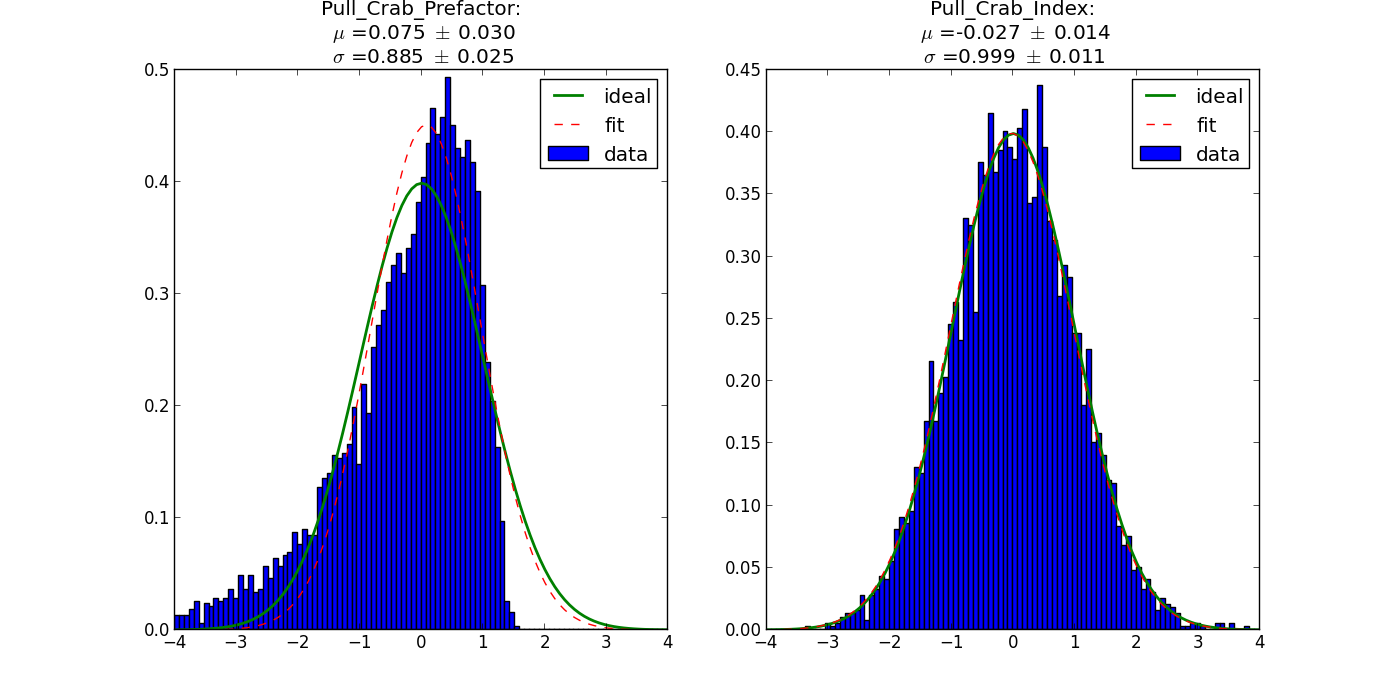
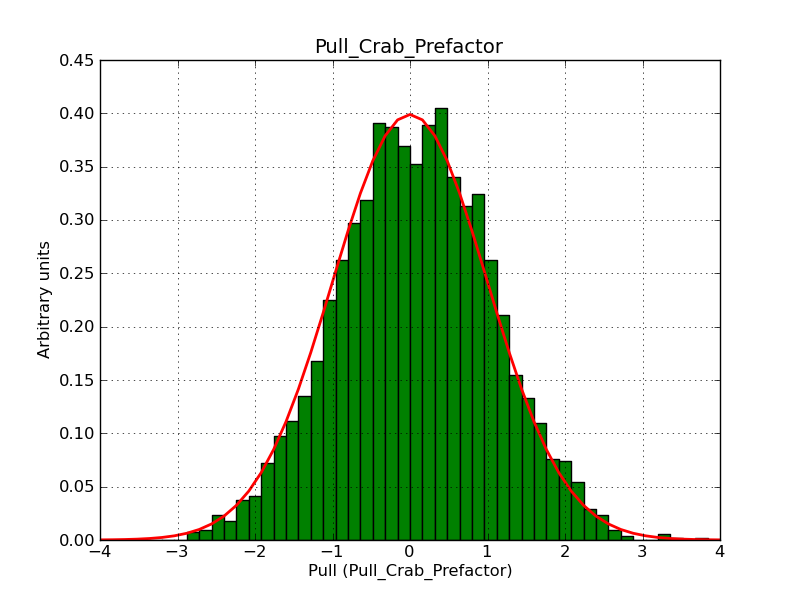
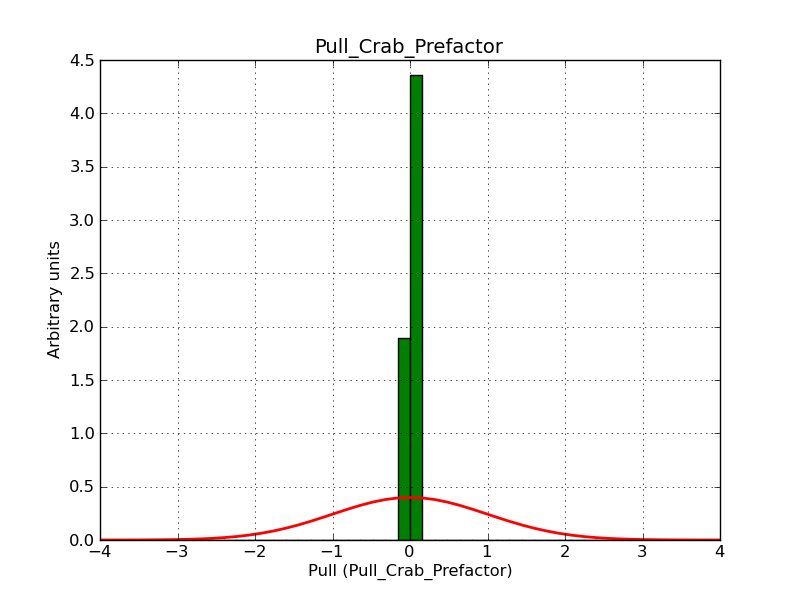
- File prefacor-fixed-scale.png added
- File prefactor-fitted-scale.png added
Below two histograms that illustrate the problem. They show the pull distribution for the prefactor for a fixed (left) and fitted (right) pivot energy. For a fixed scale factor the distribution is okay, for a fitted scale factor the distribution is way too narrow because of the degeneracy of the fit parameters.
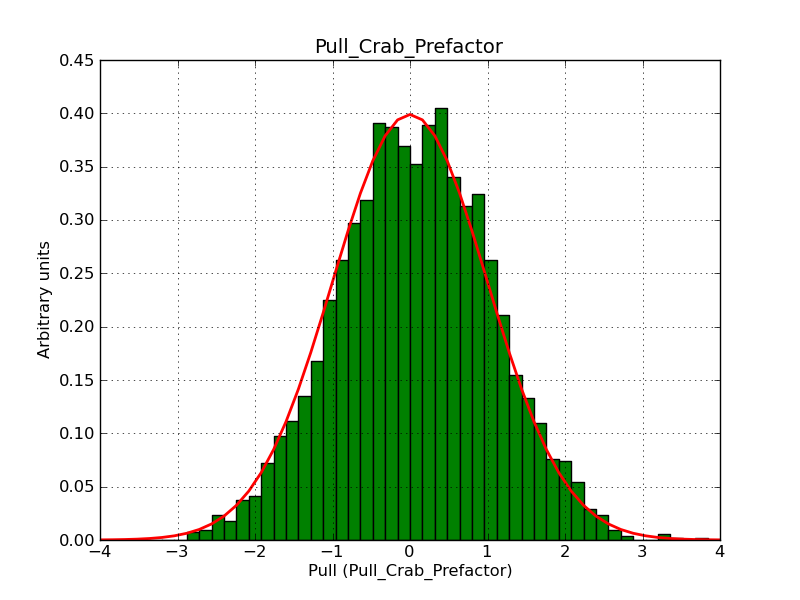 |
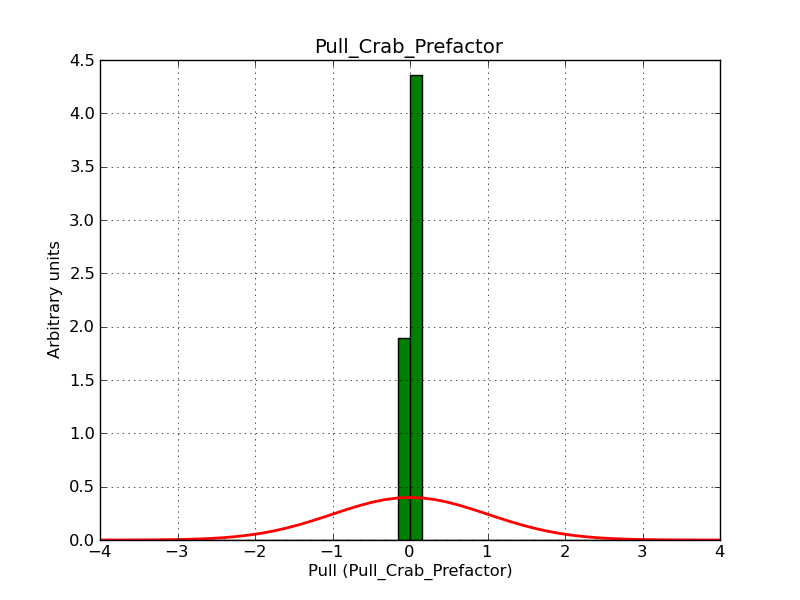 |
I also played more with the broken power law model and found that the prefactor histogram becomes wider (though not perfect) when the indices are becoming significantly different (for example -2 and -4). This also illustrates that the problem is due to the degeneracy of parameters.
I also looked in the analytical form of the Hessian matrix, but could not see an obvious reason why the approximation that is used should be particularly bad. Maybe it’s more related to the fact that degenerate parameters do not make a lot of sense anyways.
Note that for Fermi/LAT, there is also the BPlaw2 model that avoids the degeneracy problem by using the integrated flux as parameter (similar to Plaw2). I guess this is the proper way to go if break energies should be determined reliably.
#13
Updated by Knödlseder Jürgen about 11 years ago
Schulz Anneli wrote:
Hi Jürgen,
you are right. Extending the simulated exposure time and fixing the Breakenergy solves the problem with the pull distributions. Thanks. This means that the feature is now implemented and ready to be merged in the devel branch. Or is there something else to do?
I’ll merge the broken power law into the devel branch. We still have the caveat of the error determination for the prefactor and the break energy, but the class itself seems to be fine.
#14
Updated by Knödlseder Jürgen about 11 years ago
- Status changed from In Progress to Closed
- Target version set to 00-08-00