Feature #1039

Allow usage of energy threshold given by a FITS header keyword
| Status: | Closed | Start date: | 12/11/2013 | |
|---|---|---|---|---|
| Priority: | High | Due date: | ||
| Assigned To: |  Mayer Michael Mayer Michael | % Done: | 100% | |
| Category: | - | |||
| Target version: | 1.0.0 | |||
| Duration: |
Description
In IACT analysis, every run has its own safe energy threshold, depending on pointing position, muon efficiency, etc. This value can be provided in the FITS header of the event list. Probably ctselect or ctbin should have a boolean option e.g. use_thres, which specifies wether the user wants to apply the energy threshold specified in the event list.
I propose to use E_THRES as header keyword.
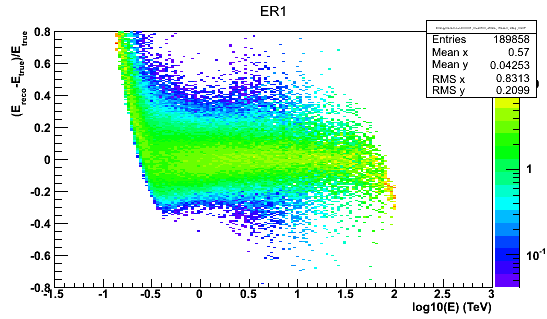
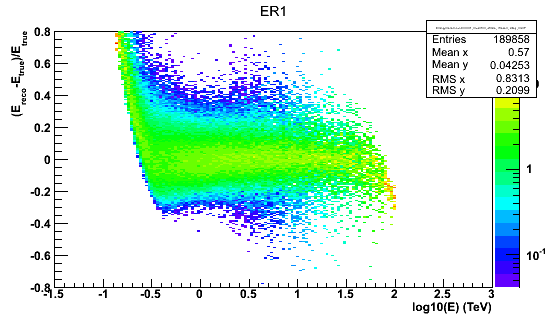
ER1.png - Energy resolution matrix stored in format #1 in Heidelberg HAP (20.7 KB)
{kind=link}
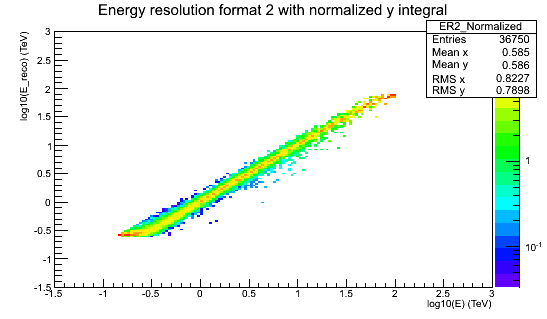
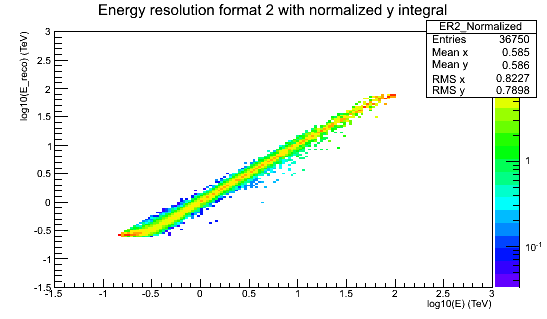
ER2_Normalized.png - Energy resolution matrix stored in format #2 in Heidelberg HAP (10.9 KB)
{kind=link}
obslist.py  (10.1 KB)
(10.1 KB)
Recurrence
No recurrence.
History
#1
 Updated by Knödlseder Jürgen about 11 years ago
Updated by Knödlseder Jürgen about 11 years ago
- Target version set to HESS sprint 1
#2
Updated by Knödlseder Jürgen about 11 years ago
- Target version changed from HESS sprint 1 to 2nd coding sprint
#3
 Updated by Deil Christoph about 11 years ago
Updated by Deil Christoph about 11 years ago
There doesn’t seem to be an OGIP convention (a bit surprising):
http://heasarc.gsfc.nasa.gov/docs/heasarc/ofwg/docs/spectra/ogip_92_007/node6.html
At the moment to run spectral analyses of HESS data with Sherpa, the START exporter puts this in the PHA (the binned counts file) header:
ETH = 641210937.5 / Energy threshold of the run
So it’s up to CTA to define where this goes.
Some thoughts:- We need a minimum and maximum safe threshold. (The maximum safe threshold is not often needed, but there are a few cases where it matters.)
ENERGY_SAFE_MINandENERGY_SAFE_MAXsounds descriptive to me, but we have to pack it into 8 characters, right?ESAFEMINandESAFEMAX? - It’s not clear to me if the event list is the right place to put this info or if one of the IRF files would be better. The natural place to compute the safe energy threshold is when accessing the effective area and energy resolution lookups, not when processing events. But I don’t really have an opinion where it should go.
Karl, are you still in charge of the CTA FITS event list format?
Could you add safe energy info to this document and put a link to the updated draft here?
#4
Updated by Deil Christoph about 11 years ago
Concerning ctools options: the default should definitely be to apply the threshold.
There are cases where in the HESS software we get visible systematics in the spectrum (i.e. too low or high first flux points) when applying the default energy threshold. That’s why I implemented these options in HAP:
--Spectrum/AllowedEnergyBias
Used for debugging only, do not change for publication.
The safe energy threshold is defined by a certain energy
bias, which is 10% by default.
Default is: 0.1
--Spectrum/EnergyBiasFactor
Used for debugging only, do not change for publication.
Multiplicative factor for the energy bias. 1 will give the
normal threshold defined by AllowedEnergyBias, 0 will
effectively turn the safe energy cut off completely, in
the past sometimes used 1.1 or 1.2 to get rid of a flux
point with high systematic errors at the threshold.
Default is: 1
It could be useful to have an option like the EnergyBiasFactor that controls how safe the threshold should be, i.e. have a factor to control instead of just a use_safe_energy_threshold option.
#5
Updated by Knödlseder Jürgen about 11 years ago
Deil Christoph wrote:
There doesn’t seem to be an OGIP convention (a bit surprising):
http://heasarc.gsfc.nasa.gov/docs/heasarc/ofwg/docs/spectra/ogip_92_007/node6.htmlAt the moment to run spectral analyses of HESS data with Sherpa, the START exporter puts this in the PHA (the binned counts file) header:
[...]So it’s up to CTA to define where this goes.
Some thoughts:
- We need a minimum and maximum safe threshold. (The maximum safe threshold is not often needed, but there are a few cases where it matters.)
ENERGY_SAFE_MINandENERGY_SAFE_MAXsounds descriptive to me, but we have to pack it into 8 characters, right?ESAFEMINandESAFEMAX?- It’s not clear to me if the event list is the right place to put this info or if one of the IRF files would be better. The natural place to compute the safe energy threshold is when accessing the effective area and energy resolution lookups, not when processing events. But I don’t really have an opinion where it should go.
Karl, are you still in charge of the CTA FITS event list format?
Could you add safe energy info to this document and put a link to the updated draft here?
Couldn’t the data themselves also be used for determining a save threshold? In first approximation, the counts per energy should mimic the effective area at the threshold. Could you explain a little more how the safe energy threshold is determined?
And what is the reasoning behind the maximum threshold? Does this also vary from run to run, or is this just a way to get rid of low counts regions?
#6
Updated by Knödlseder Jürgen about 11 years ago
Deil Christoph wrote:
Some thoughts:
- We need a minimum and maximum safe threshold. (The maximum safe threshold is not often needed, but there are a few cases where it matters.)
ENERGY_SAFE_MINandENERGY_SAFE_MAXsounds descriptive to me, but we have to pack it into 8 characters, right?ESAFEMINandESAFEMAX?
ESAFEMIN and ESAFEMAX are okay. We should also not forget to add the units. OGIP recommends a EUNIT keyword, see http://heasarc.nasa.gov/docs/journal/fits6.html, but I think units can also be added to the comment in square brackets (not sure if this is 100% compatible, needs maybe a check).
- It’s not clear to me if the event list is the right place to put this info or if one of the IRF files would be better. The natural place to compute the safe energy threshold is when accessing the effective area and energy resolution lookups, not when processing events. But I don’t really have an opinion where it should go.
I’d prefer the event file, for the simple reason that in ctselect where this information is needed, no IRF is supplied. Or more general: the threshold will be used for event selection, and reading the IRFs for event selection is some overhead that we’d like to avoid.
Karl, are you still in charge of the CTA FITS event list format?
Could you add safe energy info to this document and put a link to the updated draft here?
#7
Updated by Deil Christoph about 11 years ago
Knödlseder Jürgen wrote:
Couldn’t the data themselves also be used for determining a save threshold? In first approximation, the counts per energy should mimic the effective area at the threshold.
The safe energy threshold shouldn’t be determined from the counts, because then it would follow Poisson fluctuations.
At the moment I’m working with very clean cuts with HESS which are dominated by electron background, and there are only ~ 10 events per run.
Could you explain a little more how the safe energy threshold is determined?
In HESS there are three methods in use for the lower safe energy threshold:
A) Find the energy at which the effective area is X% (typically 10%) of the maximum effective area (which is reached at some higher energy).
B) Find the energy at which the energy bias is +X% (typically 10%)
C) Find the energy at which the differential rate peaks assuming some power-law spectral index, i.e. roughly the maximum in the (effective area) x (power law flux) curve as a function of energy.
In ParisAnalysis usually method A) is used, in HAP usually method .
Note that there is no “right” method to define the safe energy threshold, if the instrument response were correct at low energies it would not be needed at all.
The higher you put it, the safer (i.e. less likely to see systematics in the spectrum due to incorrect IRFs), but also the less sensitive, because data is thrown away.
So it is possible to compute the safe energy threshold from the effective area and / or energy resolution.
Actually now I vaguely remember that we discussed this before and decided that we would do this and not need header keywords.
Although I don’t mind putting header keywords in the event list if that makes it simpler because then `ctselect` and `ctbin` don’t need to access the IRF files.
And what is the reasoning behind the maximum threshold? Does this also vary from run to run, or is this just a way to get rid of low counts regions?
Low counts regions are fine, no need to get rid of them.
For Heidelberg HAP the reason is that there is a bias in the energy reconstruction at high energies and the energy resolution is considered unreliable where it has a bias below -10%.
The reason for the bias (I think) is that the energy reconstruction lookup is based on simulations out to only 100 TeV, so roughly by definition we will never reconstruct events with higher energies.
This leads to a pile-up of events at ~ 100 TeV and energy reconstruction above 80 TeV or maybe even sooner is unreliable.
There’s also the problem of very low statistics in the simulations that were used to produce the effective area and energy resolution IRFs for Heidelberg HAP,
another reason we want to put a safe upper energy threshold.
This doesn’t matter for most analyses because there are no events at ~ 100 TeV, but e.g. for RX J1713 and a few other analyses it does matter, and having the max. safe energy threshold keyword and applied in the tools is the future-proof way to do it.
#8
Updated by Deil Christoph about 11 years ago
- File ER1.png added
- File ER2_Normalized.png added
I’ve attached two images of energy resolution to illustrate the points I was mentioning in my last comment (regions of bias and low MC stats).
#9
 Updated by Mayer Michael about 11 years ago
Updated by Mayer Michael about 11 years ago
Yes, in Model Analysis, we use X% of the energy at the maximum effective area as energy threshold. In my opinion, the word “safe” doesn’t make too much sense because it is very subjective what “safe” exactly means. In standard analysis, a value of 10% is applied in order to have a good tradeoff between systematics and statistics. As Christoph, said, the maximum energy is just where the MonteCarlo simulation end.
In my opinion, the user should not care too much about this. The minimum and maximum energy recommended by the respective analysis/reconstruction/method should be given in the FITS header and automatically applied in ctxxx. If the user is an expert and wants to make changes he can easily pass the desired emin and emax parameters to ctselect.
#10
Updated by Knödlseder Jürgen about 11 years ago
Mayer Michael wrote:
I would even add the option to supply theYes, in Model Analysis, we use X% of the energy at the maximum effective area as energy threshold. In my opinion, the word “safe” doesn’t make too much sense because it is very subjective what “safe” exactly means. In standard analysis, a value of 10% is applied in order to have a good tradeoff between systematics and statistics. As Christoph, said, the maximum energy is just where the MonteCarlo simulation end.
In my opinion, the user should not care too much about this. The minimum and maximum energy recommended by the respective analysis/reconstruction/method should be given in the FITS header and automatically applied inctxxx. If the user is an expert and wants to make changes he can easily pass the desiredeminandemaxparameters toctselect.
emin and emax values as attributes in the XML file for an observation, so that the user can select individual emin and emax values per observation, and ctselect applies them automatically. These attributes should be optional, and a priority scheme could be implemented, such as:
- if
eminandemaxattributes are supplied in XML, use them aseminandemaxvalues of the run - else if
ESAFEMINandESAFEMAXare found in the FiTS file, use them aseminandemaxvalues of the run - else use
ctselecteminandemaxparameters
We may want to add a switch that allows to turn this logic off, imposing to use the ctselect emin and emax parameters. Alternatively, we could implement a logic where the ctselect emin and emax parameters have highest priority, and the above logic only applies if emin=None and/or emax=None (which is now supported by the parameter interface).
Or use the ctselect emin and emax as additional constraint, so that the effective emin is the maximum of the ctselect emin parameter and the ESAFEMIN value, and the effective emax is the minimum ctselect emax parameter and the ESAFEMAX value.
For ctbin things are a little less obvious, since an automatic setting of the emin and emax values would change the effective energy bin sizes. This may not be an issue at all, but maybe you want to have comparable energy bin sizes, so adjust the number of energy bins in some way. How is this done in HESS/VERITAS?
#11
Updated by Deil Christoph about 11 years ago
I would suggest to implement it like this (that’s what we do in HAP):
The emin and emax parameters in ctselect or ctbin are common for all runs, not per-run.
This (and the energy bin sizes for binned analysis) is something the user chooses.
For a given run the actual energy cuts applied are:
e_min_run = max(e_min_select, e_min_safe) e_max_run = min(e_max_select, e_max_safe)
As default emin and emax in HAP we use 10 GeV to 1000 TeV and apply per-run safe energy cuts, i.e. “take all data where we have reliable IRFs”.
This means there are bins at low and high energy with zero counts and exposure, no problem.
Then there is a tool to compute flux points ... for this we have extra parameters (adaptive binning to have at least 2 sigma per point).
I think this we can discuss at a later time.
#12
Updated by Deil Christoph about 11 years ago
Just a general comment: I think it’s OK to discuss this at length, because it’s one of the key points to get good spectra (not dominated by systematics, don’t throw away too much exposure) and it should “just work” for end-users, with a few knobs to turn for expert end-users.
#13
 Updated by Kosack Karl about 11 years ago
Updated by Kosack Karl about 11 years ago
- Priority changed from Normal to Low
In my opinion, the safe thresholds do not belong in the header or associated with the event-list at all. Those are parameters are specific to a particular type of spectral analysis (one that assumes the energy biases and dispersions are not corrected for), and not to the event list. We don’t even use this concept in all of the HESS spectral analyses, only those that operate solely in the linear energy range. In fact, these thresholds are calculated from the IRFs in general, so the anlaysis code should use those to determine where to cut (if it needs to). In a full forward-folding spectrum scenario, you don’t need to make these thresholds at all (assuming you know your response well). I don’t like the idea of adding superfluous things to the headers of the event lists, especially since you dont’ know exactly how those event lists will be used in a particular analysis.
#14
Updated by Deil Christoph about 11 years ago
- Priority changed from Low to High
I’m putting the priority from “Low” to “High” because I think this is really important to get good analysis results with ctools.
Karl is right that the safe energy threshold is really associated with the IRFs, not the events.
Would it be a problem to pass the IRF files to ctselect and ctbin and they read this info from there?
#15
Updated by Kosack Karl about 11 years ago
I think you need to think about this in a more general way. The concept of safe energy threshold was only introduced because we generally don’t do the spectral analysis in a sophisticated way in HESS (in that we don’t really use the energy migration matrix or other IRFs in the default spectral analysis, though they areused in HAP-Fr and in ParisAnalysis). The threshold simply cuts off the non-linear parts of the migration matrix, so that you can assume there are no biases.
The real concept that we should support are valid ranges for dimensions in an IRF, which is more general than an ETHRESH keyword. FOr every IRF axis, you should be able to specify the valid range (there may actually be a standard for that, but I don’t remember - there is certainly one in the VO documentation). For the energy axis, that may be simply the lowest energy bin up to the maximum energy where there is no bias from the maximum simulated energy. That’s not quite the same thing as a “safe threshold” (which was always kind of a hack concept). Instead, in the analysis that you are doing, you should allow the user to apply an appropriate threshold. If they are using the migration matrix in the specral reconstruction, then the lower-energy threshold can be the lowest bin in the IRF. If they are using a simple spectral reconstruction that assumes that E_true is linearly dependent on E_reco, then the threshold should be calculated (on-the-fly) from the migration matrix (or via a separate ctool).
I guess my main concern is that you are mixing the concept of analysis options (something the user chooses, based on which analysis algorithm they use) and meta-data associated with the event-lists themselves. How to choose the energy range is an analysis option, not specific to the data, so it shouldn’t be a header keyword. The only keywords that I would support are ones that give the valid ranges for IRF dimensions (independent of analysis method), which tells you which bins should not be trusted in the IRF due to low stats, or insufficient simulations, etc.
If you hard-code safe energy threshold somewhere, that means it must be calcualted somewhere in advance, and the user has no choice in the matter (which is not the case). Also, where is it calculated?
Wouldn’t it be simpler (and more ftools-like) to simply do something like the following:
ctsafeenergy migrationmatrix.fits method=bias value=0.10
-> that could append a keyword or write an output file with EMIN, EMAX
ctselect 'ENERGY>EMIN and ENERGY<EMAX' events.fits selected.fits
ctbin selected.fits ...If a user wants to use the full energy range (and correctly use the migration matrix in the spectral analysis), they they can just skip the first 2 steps.
You could instead imagine making a CTOOL that calculates it based on the users input (much better than wrapping all options into ctbin). So in the case that the user wants to do a simple spectral anlysis with no migration matrix, they could simply run ctsafeenergy migrationmatrix.fits method=bias value=0.10
#16
Updated by Deil Christoph about 11 years ago
I think Karl’s idea of having regions in X, Y, Energy (and possibly other parameters) where IRFs are “good” is nice.
This is a long-term project though and probably (min, max) ranges will not be enough (e.g. the energy threshold is higher at higher offsets from the FOV center).
For now I suggest we continue only looking for the best way to get a simple safe energy threshold into the ctools analysis.
The main remaining question is where it should come from:
A) header keyword event list (optional)
B) the observation definition XML list
C) header keyword in one of the IRF files
D) computed on the fly from the IRF files
All options would work and have advantages and disadvantages, I think.
If I understood correctly, Jürgen proposed above. This would be very flexible, the user could choose thresholds as they like and there could be a simple ctool like Karl mentioned that computes good default values, like where the energy bias becomes 10%.
Sounds good to me and I volunteer to write a small script to generate observation definition lists (will make separate issue for that).
#17
Updated by Knödlseder Jürgen about 11 years ago
Deil Christoph wrote:
For now I suggest we continue only looking for the best way to get a simple safe energy threshold into the ctools analysis.
The main remaining question is where it should come from:
A) header keyword event list (optional)
B) the observation definition XML list
C) header keyword in one of the IRF files
D) computed on the fly from the IRF files
If we don’t want to have this information in the header I would indeed think that option is the most flexible one. We can then have a ctool that takes and input XML file with the associated response information, and creates an output XML file with emin and emax attributes for each run. The user would then have full control on how the emin and emax values are determined. And this also fits nicely in the ftools-paradigm, where you have one tool for one task, allowing for a flexible implementation of workflows.
Karl: The @ctselect tool does in fact append data selection keywords to the output event lists in a way similar to the Fermi science tools, as I need to know for an unbinned analysis what energy range is covered (and also what spatial and temporal range). Since the ctselect output is however under user control, this should be not an issue, I guess.
#18
Updated by Deil Christoph about 11 years ago
Jürgen, could you please create a concrete TODO list? (feel free to assign me to any parts where I might be useful)
In a week I will have forgotten all the details what we have discussed and then I don’t want to re-read all of the discussion.
:-)
One more question: is the “observation definition” XML file format defined anywhere?
If not, can you document it?
#19
Updated by Knödlseder Jürgen about 11 years ago
GCTAObservation: add memberGEbounds m_save_energyto class and methods to set/get the energy boundariesGCTAObservation::read: read optionaleminandemaxattributes and store inm_save_energy(should be empty if boundaries do not exist)GCTAObservation::write: writeeminandemaxattributes is something has been stored inm_save_energyctselect::select_events: modify section that starts withsprintf(cmin, "%.8f", m_emin);so that the minimum and maximum conditions discussed earlier are taken into accountctbin::bin_events: modify section that starts withGEnergy emin(m_emin, "TeV");so that the minimum and maximum conditions discussed earlier are taken into account
I hope that’s all.
I’d propose the following XML format for unbinned
<observation name="..." id="..." instrument="..." emin=xxx emax=yyy>
<parameter name="EventList" file="..."/>
<parameter name="EffectiveArea" file="..."/>
<parameter name="PointSpreadFunction" file="..."/>
<parameter name="EnergyDispersion" file="..."/>
</observation>
and the following for binned
<observation name="..." id="..." instrument="..." emin=xxx emax=yyy>
<parameter name="CountsMap" file="..."/>
<parameter name="EffectiveArea" file="..."/>
<parameter name="PointSpreadFunction" file="..."/>
<parameter name="EnergyDispersion" file="..."/>
</observation>
#20
Updated by Knödlseder Jürgen over 10 years ago
- Target version changed from 2nd coding sprint to 3rd coding sprint
For the moment we actually decided to store the information in the ARF using the keywords
LO_THRES HI_THRES
#21
Updated by Mayer Michael over 10 years ago
Currently, there is no functionality available to to read these keywords from the Aeff-file. I propose to add a method like set_erange(GEnergy& emin, GEnergy& emax) to GCTAObservation, which is e.g. called when reading the effective area file.
These values can then be passed to the GCTAEvents as energy boundaries which are then considered in ctlike.
#22
Updated by Knödlseder Jürgen over 10 years ago
I think that logically this information is part of the response (and specifically the effective area) hence I would also put it there. We then just need to make sure that the information is accessible in ctlike. I see no principal problem, but it may be that some method needs to be added.
#23
Updated by Mayer Michael over 10 years ago
I think the question we need to discuss is whether we want the energy threshold to be applied on the fly (while reading the events and irfs).
An alternative would be to prepare the data in a separate step before passing it to ctlike. For the latter, we could write a ctool (or cscript), which loops over a given list of runs/observations, cuts according to the energy threshold (or other user preferences). The new eventlists are stored separately and already contain the necessary DS-Keywords. The tool could further create a proper XML observation file (pointing to the newly created FITS event files). Such a file could then be passed to other ctools such as ctlike.
#24
Updated by Mayer Michael over 10 years ago
- Target version changed from 3rd coding sprint to 1.0.0
We might want to think about handling this issue before the 1.0 release.
#25
Updated by Knödlseder Jürgen over 10 years ago
Agree to handle this in release 1.0.
This has become a long thread of discussions and I’m not sure whether a clear picture has emerged about what needs to be done.
Let me summarize to see whether I understand the relevant issues:- we want to apply a run-wise lower energy threshold
- the lower energy threshold information will come from the IRF; it should live under GCTAResponse
- do we want user defined lower energy thresholds?
- do we need an upper energy threshold?
#26
Updated by Mayer Michael over 10 years ago
Knödlseder Jürgen wrote:
Agree to handle this in release 1.0.
This has become a long thread of discussions and I’m not sure whether a clear picture has emerged about what needs to be done.
Let me summarize to see whether I understand the relevant issues:
- we want to apply a run-wise lower energy threshold
yes
- the lower energy threshold information will come from the IRF; it should live under GCTAResponse
yes, but the value should be more a recommendation (which is also applied per default). If the user wants to do sth different, it should be possible
Open questions to me are:
- do we want user defined lower energy thresholds?
in my view, the user should somehow be able to control both (low and high thresholds). E.g. to reduce the systematics, the user might want to increase the low energy threshold.
- do we need an upper energy threshold?
Definetely yes. The reconstruction is not perfect. Therefore an event reconstructed with e.g. 2000 TeV can happen but should be omitted.
Currently, I have to run cteslect on every single run I load into memory to apply the individual energy threshold (which is user-defined in my case, too). The question is if we want to have a preparatory step where the energy threshold is applied to the data (e.g. ctprepare or ctcut), or do we want ctlike, i.e. the optimiser to automatically consider these values.
I actually liked the idea of having the information in the observation XML file. It gives more flexibility to the user. In the future, the user might download such an XML file from a server anyway. The recommended thresholds could be already in it. If the user then wants to make changes, it is easily possible. We could also provide an xmlbuilder where the user just has to give the path to the fits files, and a list of runs to be used. This script can be adapted if the user is up for more fancy things.
We also should make sure that ctselect will respect the applied energy threshold (and other cuts). I raised issue #1351 for that.
#27
Updated by Knödlseder Jürgen over 10 years ago
Some follow up questions:
Mayer Michael wrote:
Let me summarize to see whether I understand the relevant issues:
- we want to apply a run-wise lower energy threshold
yes
- the lower energy threshold information will come from the IRF; it should live under GCTAResponse
yes, but the value should be more a recommendation (which is also applied per default). If the user wants to do sth different, it should be possible
Open questions to me are:
- do we want user defined lower energy thresholds?
in my view, the user should somehow be able to control both (low and high thresholds). E.g. to reduce the systematics, the user might want to increase the low energy threshold.
Would you need a specific user definable threshold per run or just a global threshold that is applied to all runs? If it’s per run, how do you usually decide on this? By hand or in some automatic fashion by inspecting the data or the response (or something else)?
- do we need an upper energy threshold?
Definetely yes. The reconstruction is not perfect. Therefore an event reconstructed with e.g. 2000 TeV can happen but should be omitted.
Okay, so lower and upper threshold, default values from IRF and user values to overwrite the default values.
Currently, I have to run
cteslecton every single run I load into memory to apply the individual energy threshold (which is user-defined in my case, too). The question is if we want to have a preparatory step where the energy threshold is applied to the data (e.g.ctprepareorctcut), or do we wantctlike, i.e. the optimiser to automatically consider these values.
I see. This can certainly be streamlined. I would rather think about evolving the ctselect tool instead of creating a new tools for this specific case.
I actually liked the idea of having the information in the observation XML file. It gives more flexibility to the user. In the future, the user might download such an XML file from a server anyway. The recommended thresholds could be already in it. If the user then wants to make changes, it is easily possible. We could also provide an
xmlbuilderwhere the user just has to give the path to the fits files, and a list of runs to be used. This script can be adapted if the user is up for more fancy things.
So this looks like if you want to have the possibility to adjust the threshold on a run-by-run basis. If this can be done in some automated way (for example by some algorithm) it would probably good to have a specific ctool that goes over an XML file and sets the threshold for each run (e.g. ctthres). So just a tool that writes attributes to the XML file, the selection job would then be done by ctselect in one shot.
Still, if we have default threshold information in the response I would also support the idea of using this on the fly in case that no information is provided in the XML file. Still need to think about the best way to do that. We may implement this later. Once we have the XML thing going we probably get a better feeling on how things should be organised.
We also should make sure that
ctselectwill respect the applied energy threshold (and other cuts). I raised issue #1351 for that.
Agree. This should be an easy fix.
#28
Updated by Mayer Michael over 10 years ago
- File obslist.py added
Would you need a specific user definable threshold per run or just a global threshold that is applied to all runs? If it’s per run, how do you usually decide on this? By hand or in some automatic fashion by inspecting the data or the response (or something else)?
Currently, I use a more conservative threshold than recommended by the HESS Software. The exact procedure is a bit too complex to explain here but in every zenith angle band (e.g. 0-18deg, 18-26deg, ...), I use a global energy threshold for each run which points into that respective band. This is due to the background model I use for HESS analyses. The model is subject to zenith angle and has its own threshold. I attach the file obslist.py, I use for loading and selecting the data. I use it like this:
import obslist hess_list = obslist.hess_obslist(runlistfile) hess_list.load() obs = hess_list.obs
Then
obs is an object of type GObservations and runlistfile is just a list of run numbers which should be loaded. The script won’t work if you don’t have the correct files at hand, but it demonstrates the needs a user might have. The script did evolve with time and therefore is probably not very efficient.
Okay, so lower and upper threshold, default values from IRF and user values to overwrite the default values.
I agree. Do we also want to leave it up to the user to choose a lower energy threshold than the recommended one?
I see. This can certainly be streamlined. I would rather think about evolving the ctselect tool instead of creating a new tools for this specific case.
I think it is is a very good idea to enhance ctselect for this purpose.
So this looks like if you want to have the possibility to adjust the threshold on a run-by-run basis. If this can be done in some automated way (for example by some algorithm) it would probably good to have a specific ctool that goes over an XML file and sets the threshold for each run (e.g. ctthres). So just a tool that writes attributes to the XML file, the selection job would then be done by ctselect in one shot.
Still, if we have default threshold information in the response I would also support the idea of using this on the fly in case that no information is provided in the XML file. Still need to think about the best way to do that. We may implement this later. Once we have the XML thing going we probably get a better feeling on how things should be organised.
That sounds good! ctselect should take the XML file and apply the default energy threshold if no information is given. If however there is a runwise emin/emax given this should be taken.
I could start implementing this in GCTAObservation::read() and see how this can be wired to the data selection.
#29
Updated by Knödlseder Jürgen over 10 years ago
Thanks for the script and the information.
Yes, we should add double m_lo_ethres and double m_hi_ethres to GCTAObservation and fill this information through searching the emin and emax attributes in the GCTAObservation::read() method. I think we may have none of the attributes, either one of both or both. I guess we can simply use a value of 0.0 for “threshold not set”. GCTAObservation::write() should then write out the attributes when they are non zero. The XML is as discussed above:
<observation name="..." id="..." instrument="..." emin=xxx emax=yyy>
<parameter name="EventList" file="..."/>
<parameter name="EffectiveArea" file="..."/>
<parameter name="PointSpreadFunction" file="..."/>
<parameter name="EnergyDispersion" file="..."/>
</observation>
Then we need to add lo_ethres and hi_ethres get and set members in GCTAObservation. I’m wondering whether we may explicitly show that these are user thresholds, so we could also name them lo_user_ethres and hi_user_ethres. I’m saying this as GCTAResponse will get in the future equivalent methods for the default thresholds, that could be named lo_save_ethres and hi_save_ethres to make them distinguishable.
ctselect can then deal with both of them. We can add hidden parameters, such as useuser and usesave to instruct ctselect what to do. I guess a similar logic should apply to ctbin, ctpsfcube, ctexpcube and ctbkgcube that need to consistently handle thresholds.
#30
Updated by Mayer Michael over 10 years ago
Ok great. If we implement it that way, the uploaded script (or a new similar script) would only write out an XML file with the correct emin and emax values set. Any user with special needs can do that.
Then we need to add lo_ethres and hi_ethres get and set members in GCTAObservation. I’m wondering whether we may explicitly show that these are user thresholds, so we could also name them lo_user_ethres and hi_user_ethres. I’m saying this as GCTAResponse will get in the future equivalent methods for the default thresholds, that could be named lo_save_ethres and hi_save_ethres to make them distinguishable.
Sounds like a good idea. We should add m_lo(hi)_thres to GCTAResponse and m_lo(hi)_user_ethres to GCTAObservation. Maybe we might use GEbounds instead of double?
For usage in ctselect, we could further add the method GCTAObservation::ebounds(), which returns the correct GEbounds object according to the following hierarchy:
if (m_user_ebounds.is_valid())
return m_user_ebounds;
else if (m_response.ebounds().is_valid())
return m_response.ebounds();
else
return (GCTAEventList*)m_events->ebounds();
Then
ctselect can call obs->ebounds() instead of list->ebounds() and does not need to care where these bounds come from (Either they are set by the user, by default through the response or by a previous selection).
I won’t implement such a logic as you will loose the trace of where the ebounds come from. I would more follow the approach to apply the proper ebounds in a first place by event selection, as an event list should be consistent with the energy boundary it provides. If the logic becomes too complicated the user has difficulties to follow it.
So I would simply use doubles to reflect in fact what is written in the XML file (avoid any unit transformations). This is a general logic that I tried to follow, keep copies of XML values in the classes to be able to write them back as they were read.
I would also argue for m_lo(hi)_thres instead of m_lo(hi)_save_thres to not give the impression that one are superior to the other. At the end, it’s just the algorithm that changes behind the scenes. GCTAObservation::ebounds() exists already. I implemented this recently to be able to access the energy boundaries without loading the event file list. This becomes important for hugh datasets which cannot fit anymore in memory. ctools allow now to offload the data to disk so that memory requirements are limited. But to make this work I had to add a method that gives the event list energy boundaries in the observation.
#31
Updated by Mayer Michael over 10 years ago
I guess this has more become a gammalib-issue...
#32
Updated by Knödlseder Jürgen over 10 years ago
As it will require changes in ctselect we can keep it here I think.
#33
Updated by Mayer Michael over 10 years ago
I won’t implement such a logic as you will loose the trace of where the ebounds come from. I would more follow the approach to apply the proper ebounds in a first place by event selection, as an event list should be consistent with the energy boundary it provides. If the logic becomes too complicated the user has difficulties to follow it.
You mean ctselect should check which values have been set and applies the selection accordingly?
So I would simply use doubles to reflect in fact what is written in the XML file (avoid any unit transformations). This is a general logic that I tried to follow, keep copies of XML values in the classes to be able to write them back as they were read.
Good point. Agreed.
I would also argue for m_lo(hi)_thres instead of m_lo(hi)_save_thres to not give the impression that one are superior to the other. At the end, it’s just the algorithm that changes behind the scenes. GCTAObservation::ebounds() exists already. I implemented this recently to be able to access the energy boundaries without loading the event file list. This becomes important for hugh datasets which cannot fit anymore in memory. ctools allow now to offload the data to disk so that memory requirements are limited. But to make this work I had to add a method that gives the event list energy boundaries in the observation.
I see. So we leave this method untouched and implement the hierarchy in ctselect. Do we agree that the order should be:user_defined > response > previous selection?
#34
Updated by Knödlseder Jürgen over 10 years ago
Mayer Michael wrote:
I won’t implement such a logic as you will loose the trace of where the ebounds come from. I would more follow the approach to apply the proper ebounds in a first place by event selection, as an event list should be consistent with the energy boundary it provides. If the logic becomes too complicated the user has difficulties to follow it.
You mean
ctselectshould check which values have been set and applies the selection accordingly?
Yes. This does not exclude to also add some on-the-fly capabilities to other tools, but I won’t do this on GammaLib level as things become then difficult to trace. GammaLib should just be able to pipe through the information.
So I would simply use doubles to reflect in fact what is written in the XML file (avoid any unit transformations). This is a general logic that I tried to follow, keep copies of XML values in the classes to be able to write them back as they were read.
Good point. Agreed.
I would also argue for m_lo(hi)_thres instead of m_lo(hi)_save_thres to not give the impression that one are superior to the other. At the end, it’s just the algorithm that changes behind the scenes. GCTAObservation::ebounds() exists already. I implemented this recently to be able to access the energy boundaries without loading the event file list. This becomes important for hugh datasets which cannot fit anymore in memory. ctools allow now to offload the data to disk so that memory requirements are limited. But to make this work I had to add a method that gives the event list energy boundaries in the observation.
I see. So we leave this method untouched and implement the hierarchy in
ctselect. Do we agree that the order should be:user_defined > response > previous selection?
In fact I wanted to write the opposite m_lo(hi)_save_thres instead of m_lo(hi)_thres.
I guess user defined always overwrites any internal selection, so this should take precedence over IRF defined.
Both cannot of course contradict the previous selection, as the events are lost. So basically, instead of specifying a single [emin,emax] from task parameters, ctselect will deal with run-wise [emin,emax], where XML defined takes precedence over IRF defined.
Maybe we even don’t need a precedence hierarchy when implementing a usethres string parameter for ctselect which can be either NONE, USER or DEFAULT. We still may think whether we keep the emin and emax task parameter as a kind of general envelope, meaning that the applied energy selection can never be larger. On the other hand, this makes things again more complicated, so the best is probably to simply ignore the emin and emax task parameters if usethres is not NONE.
#35
Updated by Mayer Michael over 10 years ago
- Status changed from New to In Progress
#36
Updated by Mayer Michael about 10 years ago
- Status changed from In Progress to Feedback
GCTAObservation::read(const GXmlElement& xml)now reads XML attributes “emin” and “emax” and stores them as protected membersGCTAResponseIrf::load_aeff(const std::string& filename)reads the header keywords “LO_THRES” and “HI_THRES” if available and stores them as protected membersctselecthas a new parameter (usethres), which can be “NONE|DEFAULT|USER” as suggested.ctselecthas been extended by the protected functionGEbounds ctselect::find_ebounds(GCTAObservation* obs, const GEbounds& list_ebounds), which builds the proper energy range depending on the threshold definition algorithms.
The gammalib code is available on branch 1039-allow-energy-thresholds-via-IRF-and-XML.
The ctools code is available on branch 1039-allow-energy-thresholds-in-ctselect.
I made a few quick tests, which worked fine. I am, however, still testing if we run ctselect several times in a row.
#37
Updated by Knödlseder Jürgen about 10 years ago
- Assigned To set to Mayer Michael
- % Done changed from 0 to 80
Looks good.
I made some minor adjustments:- renamed the new method to
set_ebounds()as it does not search anything but just set the boundaries - put the
set_ebounds()call upfront inctselect::select_eventsand implement the possibility thatemin=0and/oremax=0. This allows to provide only an upper or lower threshold. - enhance the logic of
set_ebounds()so that every energy boundary value of 0.0 is ignored. This has NOT been tested so far.
On the GammaLib side, I merged the code in devel.
On the ctools side I pushed the modifications in 1039-allow-energy-thresholds-in-ctselect to allow for testing and validation on your side before merging the code in the trunk.
#38
Updated by Mayer Michael about 10 years ago
While looking at the changes I was wondering wether we also need a similar mechanism for the RoI and Gti selection? I guess for the Gtis it should be quite analogous.
For the RoI, however, it might be a nightmare to have partly overlapping regions, which have to be considered in the fit, right? We probably need a warning or error to be thrown if the user wants to do something like this:
$ ctselect ra=83.63 dec=22.01 rad=2.5
followed by
$ ctselect ra=84.63 dec=23.01 rad=2.5
The resulting RoI would not be a circle anymore, which I am not sure gammalib can handle. What do you think?
#39
Updated by Mayer Michael about 10 years ago
- Status changed from Feedback to Pull request
- % Done changed from 80 to 100
I performed some tests by consecutively running ctselect with various energy selections. At the end, the smallest energy range stays in the data selection keywords. Therefore, the code works satisfactorily.
#40
Updated by Knödlseder Jürgen about 10 years ago
- Status changed from Pull request to Closed
I merged the code into the devel branch.
Concerning GTIs, there is some code in ctselect that will take care of existing GTIs and constrain the GTIs according to the specified tmin and tmax parameters.
For the ROI, the new ROI needs always to be fully contained within the old ROI, as only circular ROIs are supported. So if the new radius of an ROI is too large it will be shrinked automatically.
#41
Updated by Mayer Michael about 10 years ago
Excellent.